选自 supaiku.com
作者:Spike Doanz
机器之心编译
「注意力实际上是对数的」?今天,一篇博客再次掀起了AI社区对注意力机制的讨论。
作者认为,Transformers 中实现的注意力机制,在计算复杂度上应该被视为对数级别的。
这篇博客,还得到了 Karpathy 的高度肯定:
有时我会在想象中的神经网络完整计算图中将其描述为「广度是免费的,深度是昂贵的」。
据我所知,这首先是 Transformer 背后的主要见解 / 灵感。我第一次真正受到它的震撼是在很久以前我读到 Neural GPU 论文的时候(https://arxiv.org/abs/1511.08228)。
另外,在「从比特到智能」中为什么还要包含 python?删除 python,我认为你可以将其减少约 10 倍,就像 llmc 一样。
我们知道,标准的注意力机制(如 Transformer 中的自注意力)计算步骤如下:
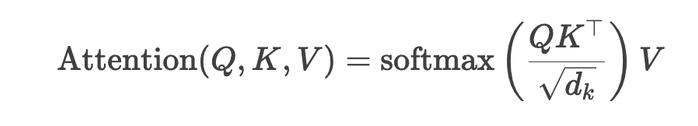
其复杂度主要来源于:
点积计算:QK^⊤ 的矩阵乘法,复杂度为 O (n^2d),其中 n 是序列长度,d 是特征维度。
Softmax 归一化:对每个位置的注意力权重进行归一化,复杂度为 O (n^2)。
一般来说,研究者认为总复杂度随着序列长度 n 呈平方增长,这也是标准 Transformer 难以处理长序列的核心瓶颈。
而这篇博客,却提出了另外一个全新的视角。
关于如何理解这一观点,我们看看博客内容便知。
博客链接:https://supaiku.com/attention-is-logarithmic
以下是博客内容:
时间复杂度是衡量算法快慢最常用的标准。在 20 世纪 80 年代,那时候计算机大多只有一个核心,大家还不知道什么是单指令多数据(SIMD)技术,所以用时间复杂度来评估算法基本是合理的。
但现在是 2025 年,单核计算机已经很少见了,就连智能手机都有 4 到 8 个核心。在这种情况下,只用时间复杂度来衡量算法的快慢就不够全面了。
举个例子来说,一个时间复杂度为 O (n³) 但能够并行的算法,和一个必须按顺序执行的算法,单从时间复杂度上看不出来它们的区别。而且,有些算法天生就是并行的,比如线性代数,但人们还在用时间复杂度来描述它们,这其实是很荒谬的。
我们需要一种更好的方式来衡量算法的复杂度。「work-depth 模型」分析提供了一个很好的思路。它不仅关注输入大小对应的操作数量,还能从理论下限的角度思考算法的复杂度。
我们不仅要考虑算法执行的原始操作数量(即「work」),更要关注计算图相对于输入大小的「depth」,也就是不可并行的顺序操作的最小数量。因为这些顺序操作是不可避免的,无论你的计算机有多少个核心,它们都会造成阻塞。
我主要研究机器学习系统的性能工程,所以接下来我会重点讨论适用于张量的算法。「work-depth 模型」虽然不完美,但很有用。
在此,我先抛出一个问题:逐个元素相乘的时间复杂度是多少?从这个问题出发,我会进一步阐述我的观点:Transformers 中实现的注意力机制,在计算复杂度上应该被视为对数级别的。
案例 1:逐个元素相乘
给定两个长度相同的向量 a 和 b,逐个元素相乘是将 a 中的每个元素与 b 中对应索引位置的元素相乘,并将结果存储在新向量 c 中(或者直接在原位置修改)。
代码如下:

从时间复杂度的角度看,这好像是线性的。如果用单线程来跑,那确实就是线性的。
然而,如果仔细观察,你会发现在这个问题的计算图中,range (n) 中的各个步骤之间没有依赖关系。它们完全独立。那么为什么不并行执行它们呢?
这正是每个线性代数 / 张量库在底层所做的事情。
你很快会发现,逐个元素相乘实际上根本不是线性时间的!它实际上看起来像是常数时间,直到达到一个神秘的临界点。
具体来说,我们可以分析逐个元素相乘时的「work」和「depth」:

算法里的每一步操作,比如加载数据、做乘法、存储,这些操作本身都不复杂,理论上只需要常数时间就能完成。只要你的计算机有足够的并行计算能力,直到某个临界点,这些操作的时间复杂度都是常数时间。
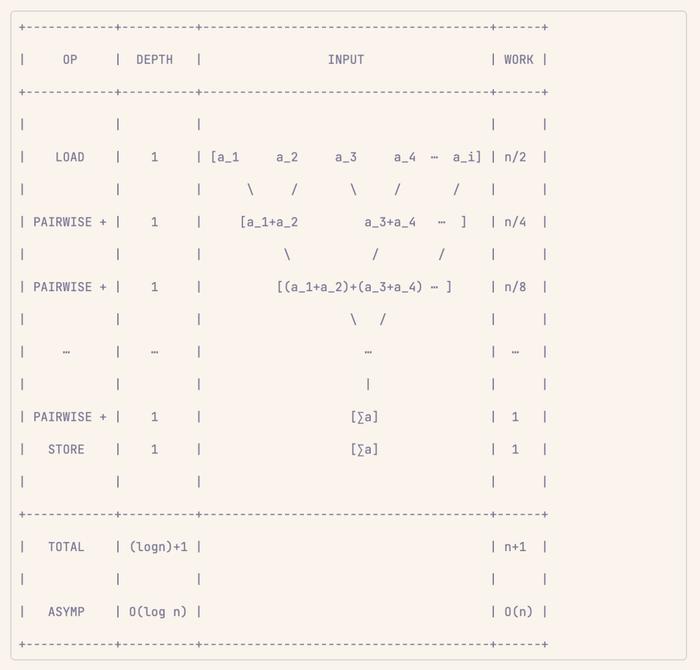
案例 2:向量求和
向量求和比相乘更复杂一些。在这里,我们可以清楚地看到两个步骤之间存在依赖关系(因为累加需要调用 c 的状态)。这无法完全并行执行。

不过,向量求和看起来好像每一步都得依赖前一步,但仔细想想,不难发现它只是每两个步骤(或者说每对元素)之间有点关联。
实际上,这个操作仍然可以并行化,方法是不在一个步骤中并行执行每个操作,而是在一个步骤中对每队执行操作。
举个例子,假设你有一个长度为 n 的列表,向量加法是这样的:
1. 先把列表里每一对相邻的数字(比如第 1 个和第 2 个、第 3 个和第 4 个……)加起来。因为一共有 n 个数字,所以会有 n/2 对。把每对的结果存到其中一个位置(比如偶数位置或者奇数位置)。
2. 再把上一步得到的每一对结果(现在每对是之前两对的和)再加起来。这次会有 n/4 对。
3. 每次都是把上一步的结果两两相加,直到最后只剩下一个数字。这个数字就是整个列表所有数字的总和。
这样一来,每次操作的步骤数量都会减半。比如,第一次是 n/2 对,第二次是 n/4 对,以此类推,总共只需要 log₂(n) 步就能把所有数字加起来。
案例 3:张量积

张量积是一个基本操作。它获取两个张量的所有索引,并对所有请求的索引(其中一些可能是共享的)逐个相乘。
比如,求两个矩阵的张量积并且共享一个轴的时候,结果会是一个三维的张量。不过,这个操作其实并不复杂,因为它只需要做并行的加载、存储、逐个相乘,所以它的「depth」是固定的,不会随着数据量变大而增加。
但要注意,这种情况只有在张量(或者张量的一部分)能够完整地装进缓存的时候才成立。如果张量太大,装不下缓存,那就会出现瓶颈,因为缓存不够用的时候,计算机就不得不按顺序处理数据,这时候「depth」就会增加。
张量积在机器学习里其实不太常被提到,但置换、求和、矩阵乘法、哈达玛积、直积、各种批处理操作等等,所有这些操作都可以看成是某种形式的张量积,再加上某种形式的归约(把多余的维度去掉或者合并)。
这样一来,能让复杂的张量操作变得更加系统、更有数学美感,尤其是在高性能计算和分布式系统里,用起来特别方便。
案例 4:矩阵乘法
矩阵乘法(MATMUL)就是这样一种张量运算,它通过张量积的收缩得到了优雅的描述。
给定两个张量分别为(i j)和(j k)的张量 A、B,张量乘法构造出一个张量 C,其元素 C [i,j,k] = A [i,j] * B [j,k],然后沿 j 维相加(收缩)成一个形状为(i k)的矩阵 D。(为了提高效率,C 通常不会完全实体化,而是在张量积的碎片之间进行收缩融合)。
只需忽略外轴,就可以对矩阵进行批处理 / 广播。

底层内容的伪代码:

注意,这只是将 TENSOR 顺序组合成 CONTRACT,其深度复杂度分别为 O (1) 和 O (logn):

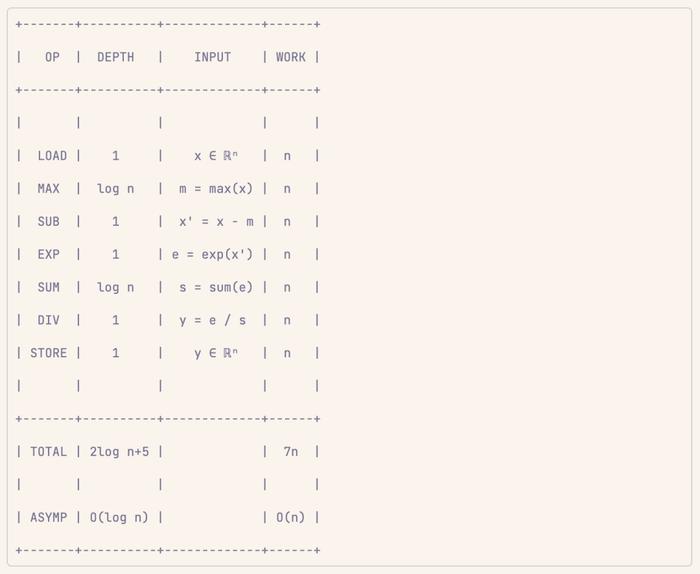
案例 5:softmax
softmax 一点也不特别。先按元素应用 e^x,然后收缩,最后按元素除法。
下面照例进行深度复杂性分析:
案例 6:注意力
注意力就不用多说了。以下是深度分析:
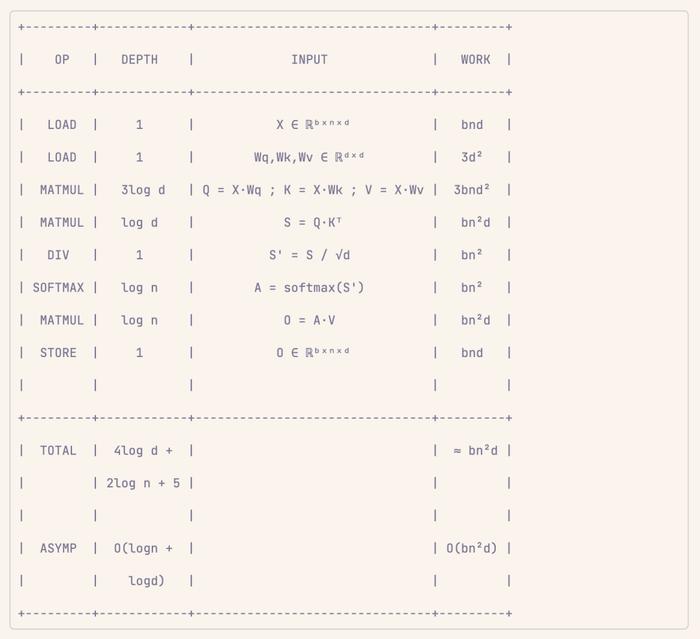
可以看到,通过整数个 matmuls 收缩和一系列元素单义操作的顺序组合,注意力的渐近深度复杂度仅为 O(logn + logd),其中 n 和 d 分别为序列长度和嵌入维数。
实际上,这通常意味着 O(log sequence_length),因为 sequence_length 通常远大于 embedding_dim。
局限性
然而,深度分析并不完美,当考虑到内存访问模式和高速缓存的友好性时,问题立即显现出来。
特别是,当出现以下情况时,该模型就会失效:
树的最大宽度 >> 计算单元(不管是什么内核)。
内存访问模式不连续 / 不可矢量化?
物化变量与内存层次结构不匹配。
在实践中,这主要意味着物化张量的大小必须保持在 L2- 左右的缓存范围内,深度复杂度边界才能成立。
那么为什么注意力不是对数的呢?
事实上,由于注意力至少需要将 QK^T 部分实体化(通常是非常大的整数,非常大的整数),这几乎肯定会溢出二级缓存(这要么迫使你在内存中计算的速度慢于 OOM,要么迫使你通过将 QK^T 矩阵分片为部分关联块并传入 softmax 来将其转化为顺序问题)。
这就意味着,对于普通计算机而言,注意力的深度复杂度更像是 O (n log n)。虽然这绝不是一个不可还原的问题,但我在下一节中会提出一些推测性的解决方案。
对未来计算的猜测?
那么,这对目前的芯片和未来的芯片意味着什么?
我认为这意味着很多,前提是一个关键事实,即训练范式在很大程度上仍然是非并发的(即看起来像循环上的前向→后向传递,或 dualpipe 之类的混合),为什么?
因为如果是这种情况,那么神经网络的权重(在 nn 次循环中占运动操作量的大部分)在很大程度上就是静态的,而且计算单元的局部性会越来越强。
我们已经看到这种情况的发生。权重曾经被卸载到磁盘或保存到内存中,只有在专门的内核中才会启动到 GPU。
后来,每个人和他们的祖母都开始完全使用设备内存(VRAM 或 HBM)进行训练。
现在,芯片制造商已经意识到,通过将权重转移到更快的内存(如 L2)上,他们可以获得另一个 OOM(在深度复杂性分析失败的地方有效地砍掉整个部分)。